估计来看此文的已经对celery有一些了解了,基本概念不再赘述。
网上找来找去全都是单机版的基础部署教程,也没有深入讲解分布式的部署过程。没办法只好靠着我渣渣英语强行研究了一波官方文档。
只有三台阿里云的服务器,不过做集群演示是够了。服务器配置比较低,所以选用redis作为消息中间件。
准备工作
实验环境:centos 6.5,python 3.4
三台服务器都装上python 3.4和celery 4.1
我pip使用的阿里云的源,默认celery版本是4.1.0,直接使用sudo pip install celery即可安装
其中一台做主服务器装上redis和mongodb,和celery的flower插件
redis做broker
mongodb用来做backend,存储任务执行结果
flower用来监测celery集群的状态
安装教程请自行搜索

注:
celery命令的详细参数请看官方文档:http://docs.celeryproject.org/en/master/reference/celery.bin.worker.html
从celery 4.0开始配置文件有所变化,具体请看官方文档:http://docs.celeryproject.org/en/master/userguide/configuration.html#example-configuration-file
queue配置:http://blog.csdn.net/tmpbook/article/details/52245716
编写代码
项目结构:

init.py
from celery import Celery
app = Celery("demo")
app.config_from_object("celery_app.celeryconfig")
celeryconfig.py
from celery.schedules import crontab
from datetime import timedelta
from kombu import Queue
from kombu import Exchange
result_serializer = 'json'
broker_url = "redis://192.168.1.2"
result_backend = "mongodb://192.168.1.2/celery"
timezone = "Asia/Shanghai"
imports = (
'celery_app.task1',
'celery_app.task2'
)
beat_schedule = {
'add-every-20-seconds': {
'task': 'celery_app.task1.multiply',
'schedule': timedelta(seconds=20),
'args': (5, 7)
},
'add-every-10-seconds': {
'task': 'celery_app.task2.add',
'schedule': crontab(hour=9, minute=10)
'schedule': timedelta(seconds=10),
'args': (23, 54)
}
}
task_queues = (
Queue('default', exchange=Exchange('default'), routing_key='default'),
Queue('priority_high', exchange=Exchange('priority_high'), routing_key='priority_high'),
Queue('priority_low', exchange=Exchange('priority_low'), routing_key='priority_low'),
)
task_routes = {
'celery_app.task1.multiply': {'queue': 'priority_high', 'routing_key': 'priority_high'},
'celery_app.task2.add': {'queue': 'priority_low', 'routing_key': 'priority_low'},
}
# 每分钟最大速率
# task_annotations = {
# 'task2.multiply': {'rate_limit': '10/m'}
# }
task1.py
import time
from celery_app import app
@app.task
def multiply(x, y):
print("multiply")
time.sleep(4)
return x * y
task2.py
import time
from celery_app import app
@app.task
def add(x, y):
print(add)
time.sleep(2)
return x + y
上传项目
写个同步文件sync.sh,方便将项目文件分别上传到三台服务器
scp -r celery_app root@192.168.1.2:~
scp -r celery_app root@192.168.1.3:~
scp -r celery_app root@192.168.1.4:~
#开始上传
chmod +x sync.sh
./sync.sh
其实不是每台服务器都需要所有的文件,只是为了方便就全部上传上去了
启动
#worker 1
celery -A celery_app -l info -n worker1
#worker 2
celery -A celery_app -l info -n worker2
#broker
/var/mongodb/bin/mongod -f /var/mongodb/conf/mongod.conf
nohup redis-server &
nohup celery -A celery_app flower -l info &
celery -A celery_app beat -l info
全部启动完成之后可以看到celery已经开始自动分配定时任务了
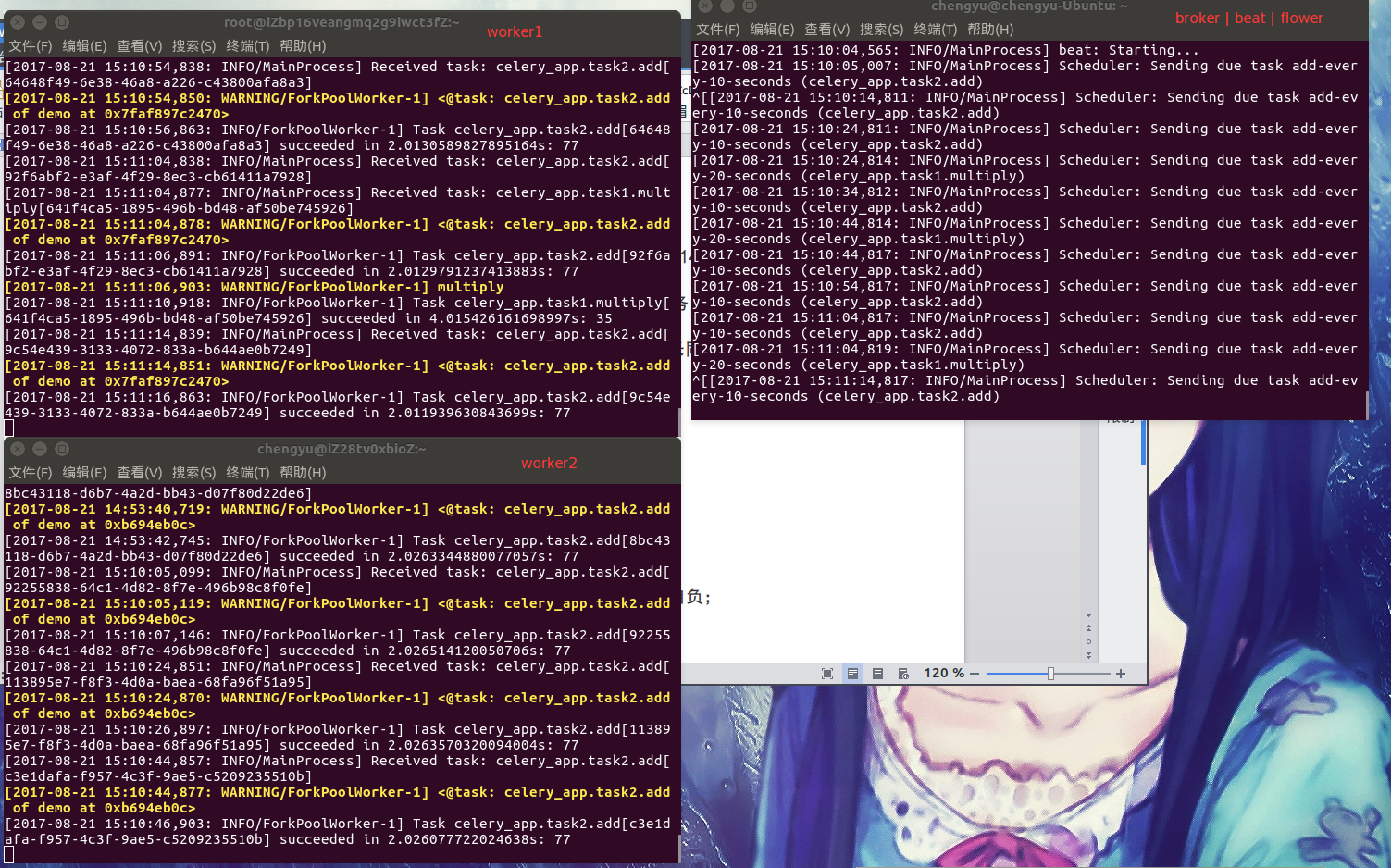
提交自定义任务
test.py
from celery_app import task1
from celery_app import task2
re = task1.multiply.delay(2, 8)
re2 = task2.add.delay(5, 6)
print("ok")
print(re.get())
print(re2.get())
输出:
/usr/bin/python3.4 /media/chengyu/Project/Github/CMSpider/test.py
ok
16
11
Process finished with exit code 0
进入flower监控服务器

可能遇到的错误
pymongo.errors.NotMasterError: not master
关闭mongodb的数据集
其他
当服务器数量较多的时候,管理起来会很不方便,可以使用python的supervisor来管理后台进程,遗憾的是它并不支持python3,不过也可以装在python2的环境
虽然用了supervisor可以很方便的管理python程序,但是还是得一个个登陆不同的服务器的去管理,咋办捏?
我在github上找到一个工具supervisor-easy,可以批量管理supervisor,如图:
地址:https://github.com/trytofix/supervisor-easy
博主请教一下,如何做backend的结果统一存储呢?最近在搭分布式集群,也是三台机,问题在于其他slave执行完任务后结果是写入txt文件中的(因为调用了外部R),而且是存储在slave本地,那么如何将结果回存到master上呢?不知博主是否有实现这方面的研究,感谢
写得比其他抄的celery博客好多了,celery核心特点在于分布式,而看了那么多博客(csdn尤甚)没有一个谈分布式服务器群处理方法,照猫画虎,最近我碰到服务器群celery问题才到处看看,还是这个好,就是不知博主的方法是根据哪个版本的celery文档写的?
4.1版本的![[-.0]](https://www.213.name/wp-includes/images/smilies/kb-emoji-U+E105.png)
https://docs.celeryproject.org/en/v4.1.0/index.html
您好博主,我想问一下各台Windows主机是通过什么建立起联系与通信的?是通过中间人redis吗?那是否需要将redis部署到云服务器上,然后设置host,port,psw等?
redis/rabbitMQ都可以,需要自己部署
楼主有没有一些推荐的系统学习资料什么的
请问几个celery worker部署在不同的机器上,消费同一个broker,是否可能出现一个task被多个worker重复消费的问题
我的broker是redis,celery是3.1.25
是否需要做特殊配置
当判定为没有执行成功时会分配给其他worker再次执行
不是指失败或者超时未返回,而是分布在不同机器/或者同一个机器的不同worker,读任务是否加锁的;创建一个task,会不会同时被发到两个消费的worker上
broker是redis时,可以用celery_once来加锁