官方的教程很坑爹,网上的教程也很少,版本扑朔迷离,很可能会因为版本不一致出各种奇葩问题,记录下我的部署过程。 nutch:1.14 solr:6.6 安装 yum install docker -y
分类归档:大数据
Spark连接mongoDB操作过程
环境: centos 7 64bit scala-2.10.5 spark-1.6.2 mongo-3.2 __ 版本不匹配可能会导致各种各样的错误,尽量使用推荐的版本 __ _ 如果遇到未知问题,请
spark、scala、hadoop环境搭建笔记
hadoop-2.6.5 scala-2.10.5 spark-1.6.2 IDEA intellj intellj scala插件 SSH免密登录 ssh-keygen touch authoriz
Intellij IDEA+spark开发环境搭建笔记
准备工具:jdk1.8 Intellij IDEA scala2.10.5 hadoop2.6.5 spark1.6.2 IDEA配置步骤: 1.添加JDK1.8 2.安装scala插件 3.
用python写个mysql-webservice同步工具
项目地址:https://github.com/chengyu2333/mysql2webservice 好像这是个看起来很智障的工具。。 你应该会说webservice直接调用数据库不就行了嘛。。
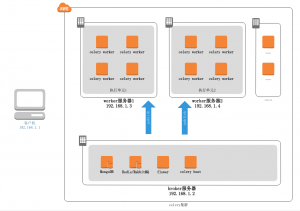
笔记:集群部署celery分布式任务队列
估计来看此文的已经对celery有一些了解了,基本概念不再赘述。 网上找来找去全都是单机版的基础部署教程,也没有深入讲解分布式的部署过程。没办法只好靠着我渣渣英语强行研究了一波官方文档。 只有三台阿里
DataFrame中的数据类型转换
想知道DataFrame中的object类型怎么转成float,很奇怪网上搜了半天没找到… 查看DataFrame中各列的数据类型: print data.dtypes 在读入文件时设置数